I am a machine learning researcher who has built large-scale multimodal systems, spanning LLMs and diffusion models for joint image, video, audio, and text generation.
My work encompasses training foundational models at Luma AI and Google Research, as well as exploring efficient training and inference techniques for video models.
I co-developed the generative video models powering Dream Machine at Luma AI (its core product) and led a team building realtime interactive video models.
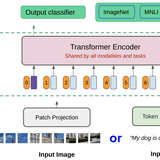
I am the first author and lead contributor of VideoPoet (2023; ICML Best Paper), a multimodal LLM for video and audio generation.
I created MoViNets (2021), a family of efficient mobile video networks enabling real-time video action recognition on mobile devices.
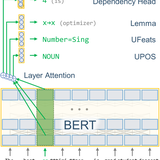
Earlier, I built UDify (2019), a single multilingual model capable of parsing the syntax of 75 languages at once.
At Luma AI I also led the World Models team, where the focus was on realtime interactive GenAI video, and included joint video-audio generation, video avatar speech-to-video, and realtime player and camera control.
Prior to Luma, I spent five years at Google Research, starting as an AI Resident and advancing to a Senior Machine Learning Engineer.
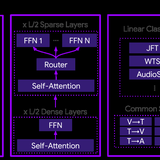
There I also worked on Integrated Multimodal Perception (NeurIPS 2023), a Mixture-of-Experts model that efficiently combines image, video, audio, and text modalities in one model, as well as research on efficient model ensembling.
I hold an M.S. in Computational Linguistics from Charles University in Prague,
earned through an Erasmus Mundus scholarship, where my thesis on multilingual dependency parsing
received the Best Master’s Thesis award from the Mathematics & Physics department.
I completed my B.S. at Boise State University,
graduating Summa Cum Laude and receiving the Outstanding Student Award in Computer Science.