I am a machine learning researcher based in Mountain View, CA.
My work spans generative AI and information theory and includes training foundational models at Google and Luma as well as academically notable research in probabilistic modeling, variational inference, and uncertainty estimation.
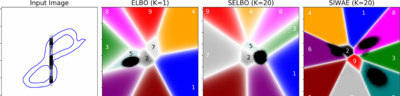
I created TensorFlow Probability (2017; 4.4k Github stars, O(1M) downloads/month still).
I co-created the prototype that would become Veo (2024).
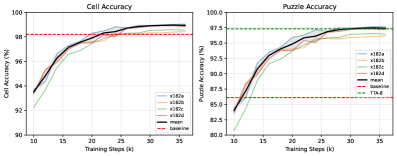
I contributed to Gemini (2024) and VideoPoet (2023; ICML Best Paper).
I designed and wrote the auction mechanism used by ContentAds (2013–2019).
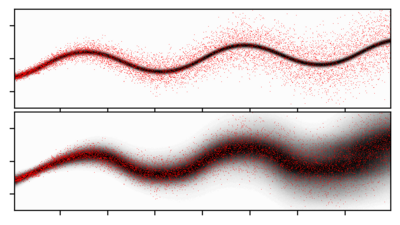
My best known paper is the Deep Variational Information Bottleneck (2017),
for which I co-developed the idea and math with my dear friend Alex Alemi.
I was a Staff Research Scientist in Google Research and Google DeepMind for a combined total of 13 years.
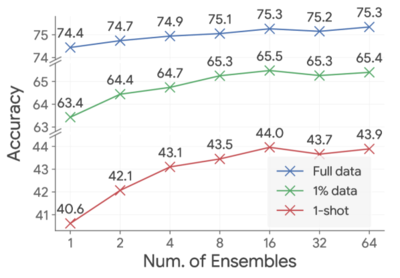
Most recently, I led the foundational model pre-training team at Luma.
I received my Ph.D. from the Georgia Institute of Technology,
advised by Professor Guy Lebanon.
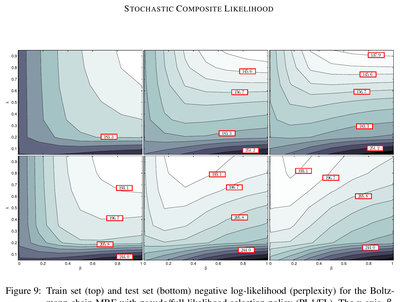
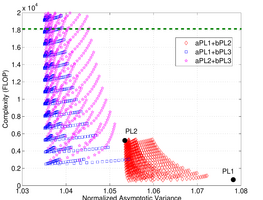
My thesis, Stochastic m-Estimators for Controlling Accuracy-Cost Tradeoffs in Machine Learning,
proposed and proved statistical properties of what would much later become known as the BERT loss.
I was awarded the DHS Fellowship in Data Analysis and Visual Analytics (2010–2012).
I also was awarded the Marshall Sherfield Fellowship for American researchers visiting the UK
(accepted to Cambridge, UK under Zoubin Ghahramani) but ultimately chose sunny California instead.