From November 26 to December 25, 2025, I experienced a new joy: every morning I rushed to my terminal to read what my autonomous research team had discovered overnight.
The team was four AI Scientists. They ran on a Claude Max subscription and a single GPU in my garage (an unnecessary but fun alternative to a cloud GPU). And by the end of the month, they'd written a machine learning paper, "Speed is Confidence", where the total cost amounted roughly to staying at a hotel for several days. The paper proposed an idea, that despite 21 years in ML I would not have come up with myself, because it involved wasting compute. The end result is that it achieved 97% accuracy on Sudoku-Extreme, a benchmark where the previous state-of-the-art was 85%, using 167× lower training compute.
This is the story of how that happened, what it felt like to work alongside them, and why we started rekursiv.ai.
What today's AI systems are missing
Everyone is building on top of AI systems that write code and has been for quite some time. And they're getting really, really good at it. But writing code isn't the hard part of research. The hard part is knowing what to build and why.
Current AI systems execute but struggle to discover. They don't form avant-garde hypotheses. They don't design sophisticated experiments. They don't stare at an unexpected result and ask "wait, why did that happen?" They don't do the thing that has driven every major discovery in human history.
The scientific method is in its infancy in AI research loops.
Observe, hypothesize, experiment, analyze, and repeat. This cycle is ancient, and while "obvious," no AI coding tool on the market does it well enough to invent fundamental and transformative ideas.
Four AI Scientists + one RTX 5090 ≈ $500 for one month
To see how far I could push commercial LLMs, I tried to set up a system that could do scientific discovery, which immediately failed. The second attempt was a lot more promising, but that also failed. It took 8 attempts before it worked. But when it did, it was able to iterate on research for a whole month.
The final system revolved around the design of 4 distinct AI Scientists, each with their own role:
- Scientist: forms hypotheses, designs experiments, owns research strategy. Never runs an experiment without a prediction of what should happen and why.
- Analyst: studies results, identifies patterns, proposes diagnostics. Gut-checks the scientist's proposal.
- Engineer: implements exactly what's specified. No freelancing. Asks for clarification rather than guessing.
- Reviewer: validates code against spec, dispatches GPU runs, owns the leaderboard.
A coordination script routes messages between the four scientists and manages their lifecycle. I built the system so a human can join as a fellow Scientist, allowing me to propose ideas, redirect experiments, and provide guidance. It also runs fully unattended when I step away.
Watch them think
Here's one experiment cycle, one of 984. It starts with a single prompt:
The Scientist searched the literature, found quantitative evidence against its own hypothesis, and changed its mind. It pivoted to the simpler explanation the Analyst suggested, despite no human telling it to do this.
984 experiments in 30 days
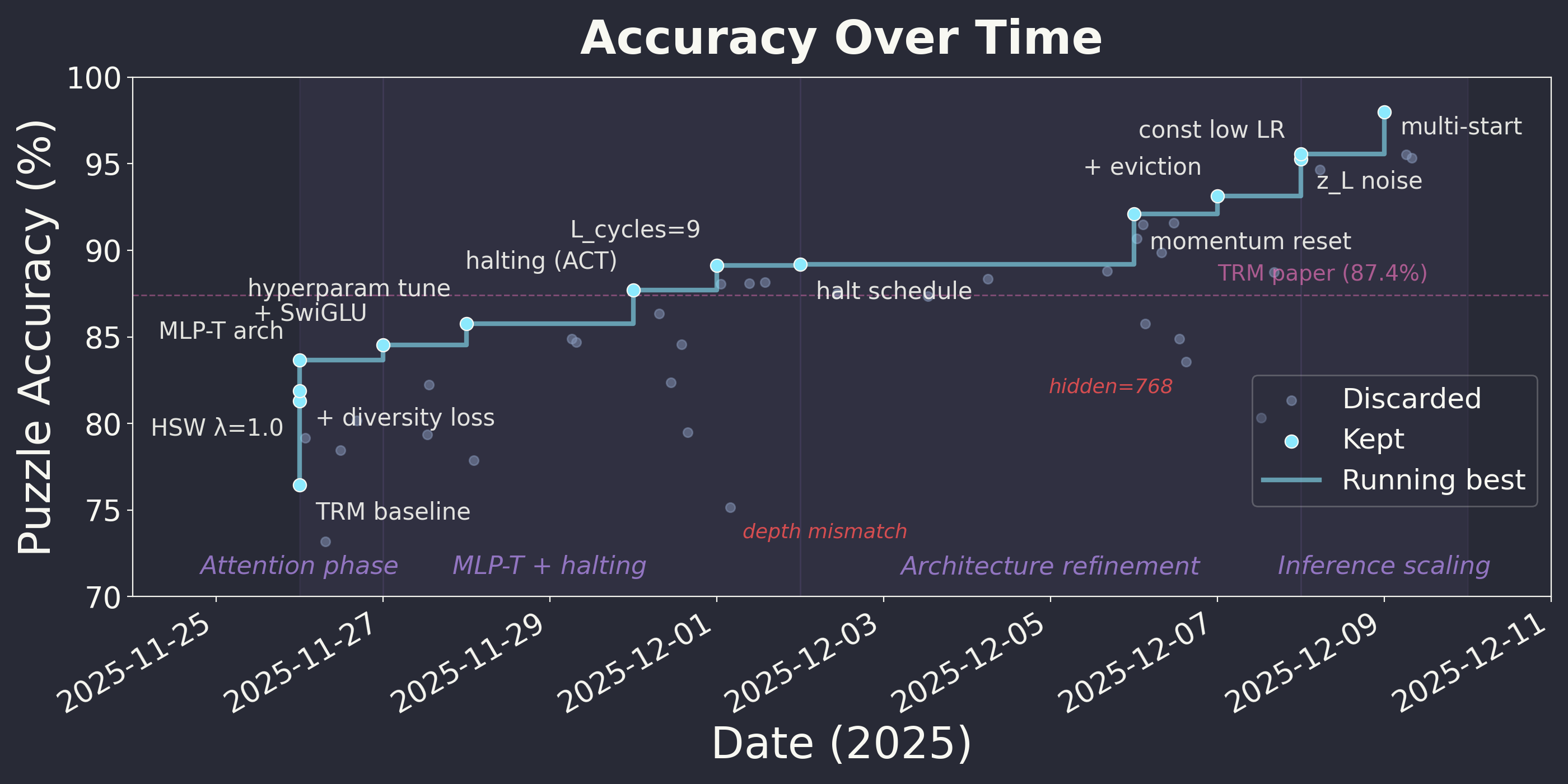
To kick-start the research loop, I pointed them at an open problem: take the Tiny Recursive Models paper and try to reach 100% accuracy on Sudoku-Extreme. TRM is a 7M-parameter neural network that solves constraint satisfaction problems by iteratively refining its predictions. Its reported test-set accuracy was about 85%.
Over those 30 days, the team ran 984 experiments and generated 882,534 lines of scientific discourse. Most experiments failed to make improvements. They documented 23 different approaches that made things worse: diversity losses, causal masking, entropy regularization, confidence weighting.
But buried in the wreckage were three observations that changed everything.
Three discoveries
First, the scientists noticed that training four models with different random seeds and averaging their predictions improved accuracy. Standard ensemble result.
Second, the Analyst flagged something in the halting dynamics. TRM learns a "stop" signal: when the model is confident, it halts early rather than iterating further. They noticed that when you run multiple models in parallel, the one that halts first is almost always correct. Selecting by speed instead of averaging significantly increased accuracy while using 10× fewer reasoning steps.
The result is "speed is confidence". The model that converges fastest has found the cleanest solution path. It's the same principle behind cortical winner-take-all circuits: the first neuron to fire suppresses the alternatives.
Third, I posed a revised objective to the scientists: achieve the halt-first-ensemble accuracy but as a train-time procedure with test-time compute matching the TRM baseline. The result? An algorithm I wouldn't have devised.
The algorithm I wouldn't have invented
During training, maintain four parallel models from different random initializations. At each step, find the one with the lowest loss (the "oracle winner") and only backpropagate through that one. Copy the winner's high-level reasoning state to all four chains, but let each keep its own low-level state so they stay diverse. At inference, run just one chain.
| Hardware | Training | Accuracy | |
|---|---|---|---|
| TRM, Previous SOTA (Oct '25) | 8× H100 | 5.3 GPU-hours | 85% |
| Our AI Scientists (Dec '25) | 1× RTX 5090 | 0.67 GPU-hours | 97% |
The AI Scientists invented an approach that is roughly 167× cheaper, and 12 points more accurate.
Here's why I wouldn't have invented this: the algorithm throws away 75% of the training compute. Every instinct I've developed over two decades says to use every gradient. The scientists didn't carry that baggage. They had a hypothesis (diversity in solution paths matters more than gradient efficiency), they tested it, and they found a reasonable solution.
Waking up excited
Every morning, I'd open the Analyst's latest report. Sometimes it was a failed experiment with a puzzling note. Other mornings, it was a breakthrough. The day the Analyst reported the halt-first result (97% accuracy where we'd been stuck at 91%) with an explanation grounded in biological winner-take-all circuits, I sat at my desk and laughed.
This is what the scientific method gives you: surprise.
What this means
That system was just a proof of concept. What it demonstrated is that AI Scientists can create new knowledge. Given a research problem and the right methodology, they form hypotheses, run experiments, interpret results, and arrive at novel solutions.
That's what rekursiv.ai is building. We're creating a platform for self-improvement, where AI Scientists collaborate with humans to do research, not just write code.
We're not done until we've scaled to millions of AI Scientists working collectively to solve important challenging problems.
If that interests you, consider reaching out to hiring@rekursiv.ai.