github.com/rekursiv-ai/copybarista
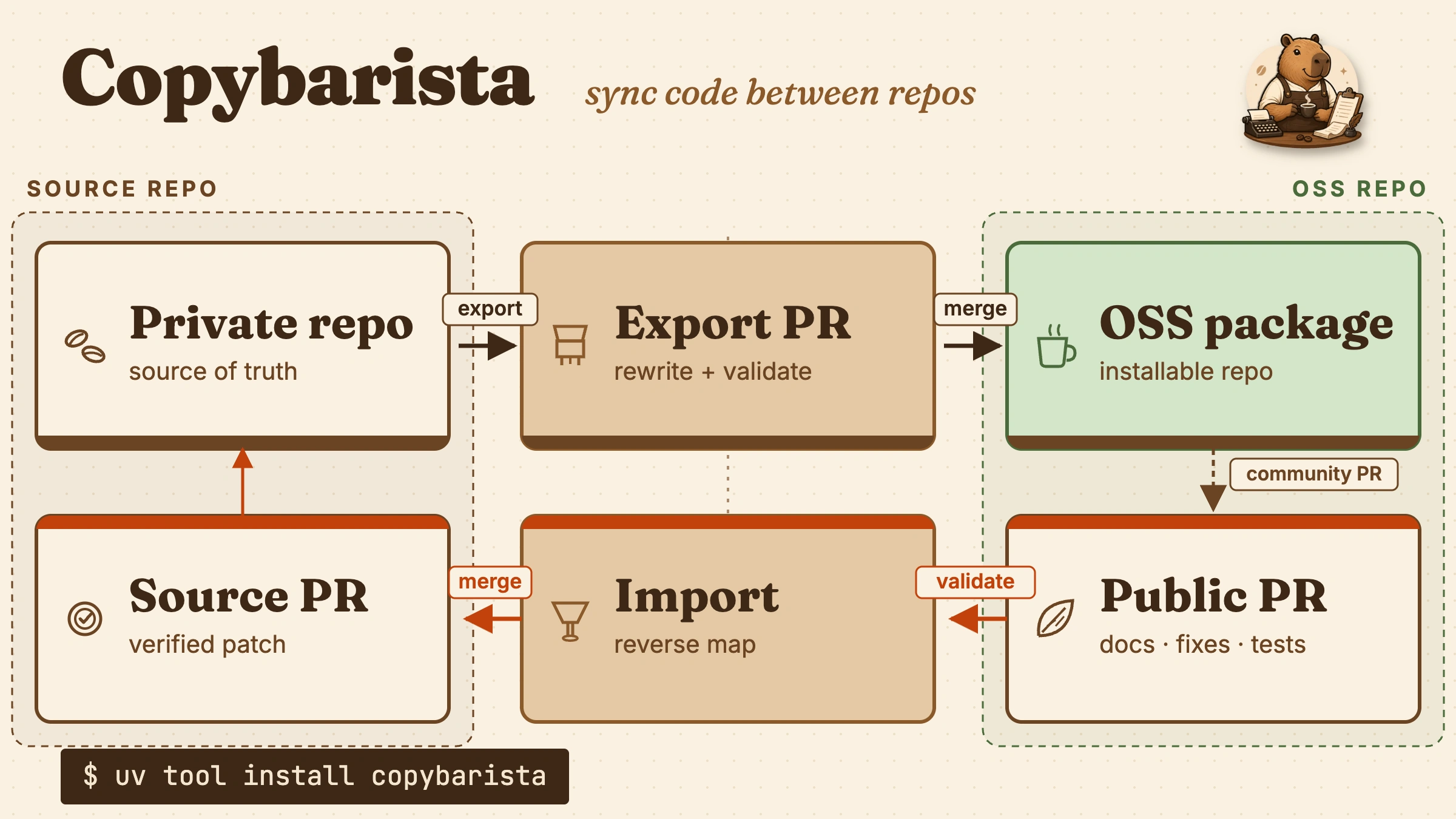
The hard part of open-sourcing code from your company's private source is not copying the files. Anyone can copy a directory from one place to another.
No, the hard part starts ten minutes later: it needs to be a normal public Python package, but the source of truth is still private. The imports point at internal modules, and README mentions internal workflow details. The GitHub Actions can push files one direction, but now someone sent a pull request and you need to send the changes back.
I wanted the boring version of this workflow: push private changes out as a clean pull request, pull public fixes back only when the reverse mapping is verifiable, and never maintain a second hand-edited copy of the package.
The first working version came together in a day of work. The release-ready version took another day of review, hardening, and documentation, but the core shape stayed small: choose a source subtree, rewrite it deterministically, export it as a clean repository, and let public fixes flow back through pull requests only when the mapping is safe.
That became Copybarista.
The problem was not copying files
The concrete case was a small Python tool inside our private monorepo. We wanted to release it as its own repository, and wanted that repository to look like a package someone would actually install:
copybarista/at the repository root- a standard
pyproject.toml, since we work with lots of ML code and loveuv - public docs and examples
- GitHub Actions for linting, type checking, tests, build, and publishing
- no private docs, source paths, internal workflow files, caches, or generated junk
The private source of truth still lived in the monorepo. I did not want to manually maintain a second copy of the package, and I did not want the open-source repository to become a fork that slowly drifted away.
The sync had to work in both directions:
- Source changes in the private monorepo should export into a public pull request.
- Public fixes should be importable back into the private source tree.
- Both directions should use GitHub's normal PR review model.
- The public repo should never receive private-only files or metadata.
- The private repo should not blindly accept public edits that cannot be mapped back safely.
At first glance, this sounds solved. Just use rsync or git subtree. Or if you want to pull out the big guns, use Copybara.
But after trying these options, I immediately ran into a great deal of friction.
Why not just use Copybara?
Copybara is the obvious comparison. Its README describes almost exactly the class of problem we had: moving code between repositories, often between a private repository and a public repository, with one repository treated as the source of truth.
I've used Copybara many times when I was at Google, it works. It supports broad repository migration workflows, transformations, and bidirectional movement. It is also intentionally general: built with a Java runtime, using a copy.bara.sky config, and a large surface area.
But I ran into a snag: I had to do a few manual steps to install a separate Java runtime, which didn't interface nicely with the Python ecosystem we were familiar with. We just wanted to run uv sync and have it available as a dependency.
I came to the conclusion that we wanted a Python-native tool for one narrow workflow:
- export a Python package from a private or monorepo source tree
- rewrite imports, docs, and private blocks
- preserve public
.github/metadata like GitHub Actions - open GitHub PRs instead of pushing directly to
main, in both directions - run verification checks before anything can ship
- easily install the tool with the rest of my Python packages using
uv
Copybara could likely be made to do most of that with enough glue, but we weren't satisfied with glue.
The design fell out of the requirements
The core design stayed simple:
config -> stage files -> transform staged tree -> write destinationThis was inspired a lot by Copybara's design philosophy, but the design is quite mature so in this case it's pragmatic to not reinvent good ideas. The basic principles lay out how to export the code and make sure the transforms are deterministic and safe. But now, it's written in a lightweight Python profile.
Export is fairly simple, coping a selected tree into a temporary directory, running deterministic transforms, then writing a folder or one clean Git commit.
Import is where things get more interesting. Copybarista compares the public tree before and after a public change, maps that diff back into the private source tree, reverses the supported transforms, and then exports again. If the new export does not reproduce the public head exactly, the import is rejected and touched files are rolled back.
That one invariant shaped the code, i.e., public changes come back only when they are reversible and verifiable.
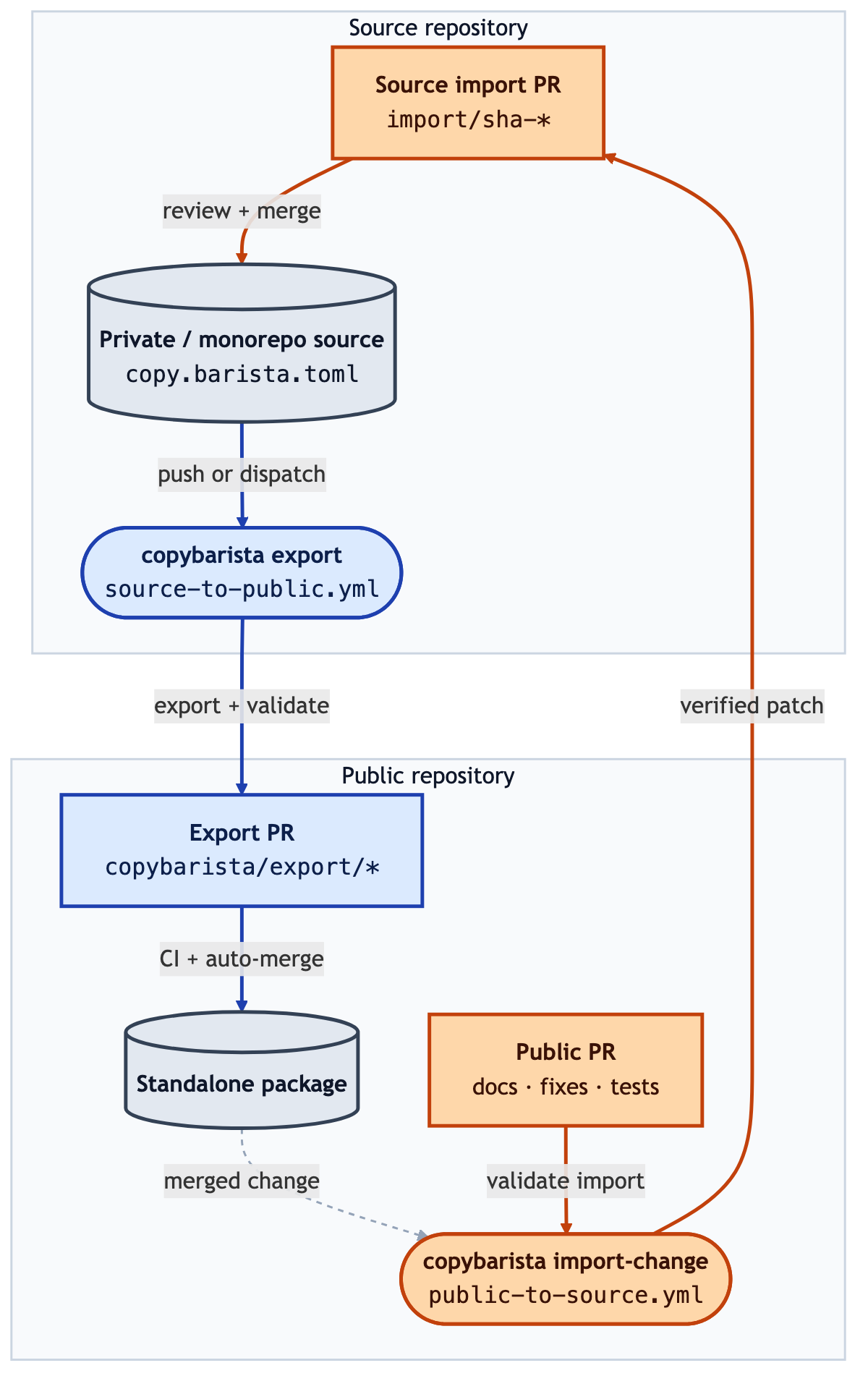
The GitHub Actions part was the real test
Once I had a basic transformation and sync working, the real test became: "Can Copybarista export itself in a safe way"? This required writing and testing the full pipeline between our source repo and a new test repo, while ensuring security best practices.
GitHub's Security Lab has written about one class of security problem in the context of Actions: untrusted pull request code should not run in a privileged context with repository write permissions or secrets. Copybarista follows the same rule. Import and validation run without GH_TOKEN. The token appears only in the final PR creation step, and that step runs trusted helper code captured before public changes are applied.
All of this in a day of work?
I truly believe we are rapidly approaching a completely new paradigm of software. It's never been cheaper to spin up a bunch of coding agents to do your bidding and write lots of code to do your task.
Now I know what readers may be thinking: "doesn't this lead to lots of unintelligible AI slop?". And if you use the coding agents in the way most people do, my answer is yes.
But that's not quite what happened (at least from my reviews and testing). The results seem to paint a different picture: the code has docstrings that explain intent, is fully typed, has 90+% test coverage, was tested with a profiler to ensure fast execution, and uses a clean set of abstractions. The repo also contains lots of documentation, tutorials, and examples, and withstood my manual testing. The first time I ran Copybarista to export itself, it just worked out of the box.
The coding workflow was not "ask for a tool, receive a tool." It was: state a desired end goal, describe the workflow, and write and rewrite a spec 3 times over. I spent a couple of hours just going back and forth to design the right set of core primitives. Once that was done, the task was to implement the smallest working version, run tests, and then harden the implementation by having multiple agents run the software manually as if a person would.
The human part was scope control. Without a narrow target, the agents would rathole in some unimportant direction, so watching the shape of the APIs between major module rewrites was important. The project was able to stay on track because the answer to many changes was "no, we don't need that yet, let's try a simpler way."
What came after the first day
Now I should mention that technically it did take an extra half-day to polish the implementation. The first working version was functional, but not ready for release. That is the part that I underestimated the most. A tool can work internally long before it is ready for strangers. Making it open-source-ready meant writing more solid documentation and examples, setting up PyPI, deciding what happens when a public PR cannot be reversed, when an export PR goes stale, etc. The answers became docs, tests, and workflow rules.
What Copybarista is, and what it is not
Copybarista is for Python projects where the source of truth lives inside a private repository or monorepo, but the package should be released as a clean standalone repository.
It is good at:
- exporting a selected tree
- rewriting imports and docs and stripping private blocks
- keeping GitHub PRs as the sync interface
It is not trying to be:
- a full Copybara-compatible migration engine
- a replacement for human review
The lesson
The surprising part was not that AI helped write code quickly, but rather how it's still possible to move fast and yet write battle-hardened, clean, and working software that does its job.
Copybarista was a test in seeing how far we can push making OSS software in the new paradigm of coding assistance tooling. And it makes me excited to see all the cool software people build.
With the right approach, you can now move fast and not break things.